
Technology Failure Is Becoming an Economic Problem, Not Just an IT Problem
Date: 14/07/26
By: Digiterre
What are the inherent benefits and complexities associated with building large-scale software solutions using serverless runtime on AWS Lambdas? And how can developers overcome the challenges posed by serverless architectures, such as testing, debugging, and the risk of vendor lock-in? This experience report by Senior Consultant, Daniel Le Pelley, presents an innovative approach to balance the scalability and simplicity of serverless runtime, using microservices.
As businesses and organisations continue to seek optimisation of software solutions, the serverless architecture, offering significant benefits, has been gaining ground. As the name implies, a serverless architecture is one where applications are developed and deployed without the need for managing the infrastructure. Leveraging this model, developers can focus solely on writing code, while the underlying platform takes care of everything else, from server management to scalability.
This experience report, by Senior Consultant Daniel Le Pelley, outlines the inherent benefits and complexities associated with building large-scale software solutions using serverless runtime on AWS Lambdas. It further explores how developers can overcome the challenges posed by serverless architectures, such as testing, debugging, and the risk of vendor lock-in. The main focus of the article lies in presenting an innovative approach to balance the scalability and simplicity of serverless runtime, using microservices.
The writer introduces a novel concept of deploying an entire microservice in a single AWS Lambda, thereby reducing the complexity and dependencies associated with managing numerous separately deployed components. A middleware framework, based on popular solutions like Express.js and ASP.NET core, facilitates message routing within the Lambda function.
In addressing another challenge related to varying transport types (HTTP, SQS, SNS), the paper underscores the principle that “a service should be defined by what it does, not by its transport”. This leads to the adoption of the hexagonal architecture pattern, promoting the separation of core business logic from the interfaces, which enhances modularity, reusability, and testability of the code.
The article concludes with an optimistic note on the resultant stability and scalability of the platform developed using the suggested approach. This approach allows for a focus on code rather than runtime, leading to a well-tested, reliable solution. Now over to Daniel.
Raj Jethwa, Chief Technology Officer at Digiterre
We were asked to build and design a large business-to-business software solution using serverless runtime. All the code would run entirely using AWS Lambdas, so no servers, no containers… just serverless runtime. This was because in the client’s view, it would make the whole platform easier to maintain, be massively scalable, and cheaper to run as there would not be a need to pay for idle servers.
This is completely right, to a degree, it should provide those benefits, however running everything in a serverless fashion does present some sizeable challenges.
This article sets out some of these challenges and an approach to combat them.
With serverless runtime, developers can run code without provisioning or managing servers. Instead, the service automatically scales and executes the code in response to incoming requests or events, while the developer only pays for the computing time consumed by the code.
Serverless functions are event-driven, which means they execute in response to triggers, such as an API call, a file upload, or an event on an event bus. The code runs in a sandboxed environment and has access to a set of predefined resources, such as CPU, memory, and storage, which can be customized based on the workload.
Overall, this provides a flexible and scalable platform for developers to build and run applications without worrying about infrastructure management.
This all sounds fantastic in theory; however, numerous software projects fail due to the ability to build overly complex systems from a substantial number of small serverless functions.
Debugging and testing serverless functions can be more challenging than traditional applications since the functions are typically deployed in production-like environments, and it can be difficult to reproduce issues in development.
Several different serverless functions might be similar but are deployed separately, so one change might mean multiple things need to be deployed, something that should be avoided wherever possible.
Serverless architectures often require developers to use proprietary tools and services provided by a particular cloud vendor, which can create vendor lock-in.
It is easy to simply end up with too many small components with dependencies on each other, which can lead to buggy, fragile systems that become hard to understand and difficult to change. Often things get far too complicated, and the project ends up becoming unmanageable, and in the worst case abandoned entirely.
If you can get all the advantages of using a serverless runtime but without the downsides, it would be a step-change in how large software projects can be delivered. What I want to do is explain an approach that I took to get around these downsides. All of this has been done for a large software project, it is all in production and performing very reliably and on a large scale for thousands of businesses across the UK.
Whole Microservice in a Single AWS Lambda
The first and most obvious problem to tackle is simply having too many things. I have always felt that microservices are about the sweet spot on a scale that goes from monolith (too big) to nano services (too small). They are the “Goldilocks” service size, small enough to overcome the issues of monoliths, but not too small that we start hitting the “too many things” problem.
One of the key constraints with serverless runtime is cold starts, the time taken for the serverless function to start up and start processing requests. This means they need to be small. However, when you have highly related functions, they often share a lot of similar code, which suggests they should be combined into one construct to avoid duplication.
When you start thinking this way, it is not a big step to conclude that having an entire microservice running in a single AWS Lambda makes a huge amount of sense. If 80% of your code is shared amongst related serverless functions, you can combine all these functions into a single microservice without much of an increase in the size of the serverless function. You then end up with fewer entities, with fewer integration points, which is a step-change in terms of keeping things simple.
In fact, this approach has some immediate benefits, there are fewer cold starts, fewer artefacts to deploy as functionality related to a single domain or business function is all contained in one running process, and it goes a long way to tackle your problems of simply having too many separately deployed components. And you still get the advantages of serverless, such as massive scalability with no overhead of managing servers and runtime.
There is a downside to this approach, there are now serverless functions that will perform multiple distinct functions instead of just one, and the function it performs will depend on what is contained within the payload it receives.
The good news though is this is a solved problem; we have been doing this for years with frameworks like ASP.Net and Node which route a message to something that can handle it. To solve this problem, a lightweight middleware framework was built to run inside an AWS Lambda which routes messages to a message handler, then picks up the result to create a Lambda response.
This middleware framework is loosely based on things like Express JS and ASP for .NET core, except rather than just being focused on HTTP, the transport is kept agnostic at its core so it will work with anything, which comes to the next core concept.
“A service should be defined by what it does, not by its transport”
Another problem we were presented with is that consumers of our services may want to access that functionality using different transport on AWS. Some functionality would need to be made available using SNS, some using SQS, and some available using HTTP.
A more traditional solution would be to build separate functions to handle each transport type. I am sure we are all familiar with thinking in terms of an HTTP service, or a service that listens to a queue. The point here is the transport dictates what the service is, not what the service does. This adds to our problem of “too many things” and can lead to duplication in our software.
“A service should be defined by what it does, not by its transport”.
A solution to this problem can be found in the aims of a pattern known as hexagonal architecture.
Hexagonal architecture, also known as ports and adapters architecture or clean architecture, is a software design pattern that aims to create highly maintainable and flexible applications. The pattern defines the application as a hexagon, with the core business logic at the centre, surrounded by several layers of adapters and ports that interact with the external world.
The core business logic is independent of the outside world and interacts only with abstract interfaces, called ports. These ports define the application’s input and output interfaces, such as REST APIs, message queues, or databases. By decoupling the core logic from these interfaces, the application becomes more flexible, testable, and maintainable.
The adapters layer consists of implementations of the input and output ports, which translate the data and actions of the core logic to the external world. Adapters can be thought of as translators or bridges between the application and its environment.
Hexagonal architecture emphasizes the separation of concerns and the dependency inversion principle, which allows for modular and reusable code. By focusing on the business logic and abstracting away the implementation details, the architecture promotes test-driven development and encourages the use of dependency injection and mocking frameworks.
To truly abstract the business logic from the transport there is a need to treat all transport equally. What they all have in common at their most basic level is that they are all messages.
To avoid any transport concerns reaching our business logic, the message structure needs to be as simple as possible. This was the structure that we ended up with.
{
topic: string
body: JSON
}
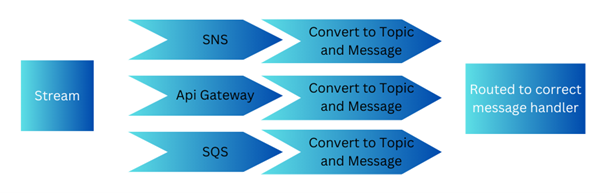
Some cloud-based transports already roughly fit with the design above. With HTTP the route defines which topic the message should map to, and the body can be constructed from the HTTP body along with any params and query strings. The point is it is perfectly possible to treat everything AWS does (HTTP, SQS, SNS, Kafka, Alexa, Kinesis, etc.) as a simple message for the purpose of achieving a hexagonal architecture within a serverless function.
When a message is received by the serverless function, firstly it needs to work out what type of message it is and push it down the relevant middleware pipeline. For example, an SNS message will be processed differently from API Gateway message. The code deconstructs the message into two parts, a topic that tells what type of message it is, and the message body.
Message Handlers
There needs to be something that handles the message, so with our Uncle Bob clean coder hat on, it seems sensible to call that a MessageHandler.
<topic>
class MessageHandler<TMessage, TResponse> {
Handle(TMessage message) : MessageResult<TResponse>
}
For each type of message we need one MessageHandler assigned to that message’s topic name. We used attributes to decorate the message handlers with the message topic name.
The message handler then has a single function; it takes in the message body and returns a response wrapped in a message result. In MVC the message handler is the equivalent of an action on a controller.
Message Result
The message result is related to the “Maybe” pattern which is common in functional programming, the Some or None pattern for those familiar with Scala and OCaml.
class MessageResult<T> {
status: string
payload: T
errors: string[]
}
The message result contains a status that represents the success or failure of the service to be able to complete the processing of the message. If it is successful, it will optionally have a payload, if it is unsuccessful, it will contain information about the reasons for the failure.
The MessageResult is there to help decouple our business logic from the transport. It is the responsibility of the hexagonal architecture to transform the MessageResult into something that makes sense for the transport we are using. For example, if the message came in over HTTP, then we need to return an HTTP response with an HTTP status code that represents the result of processing the message. If the message came in from a queue, we may want to send out a message on a message bus to inform any interested parties that a new entity has come into existence. The point here is the business logic is not concerned with what happens after it is finished processing the message, it communicates the result and that is all.
With AWS Lambdas everything comes into the Lambda as a text stream. The first step is to work out what transport has been used, de-serialize the stream and push it down the correct middleware pipeline where it gets converted into a simple message and passed to the correct message handler.
There is a certain level of discipline required to make this work, but this is the discipline of good, clean, well-defined code so is a benefit to the team and project.
It results in services that have very well defined and have very uniform behaviour, and that in a complex system makes things an order of magnitude more straightforward.
We can now think of a service as simply a collection of message topics that it can handle along with a collection of transport types it supports. One huge benefit of this approach is tooling, and this can drive auto-generation of documentation, SDKs, infrastructure code, contract testing, discoverability, etc.
Using a hexagonal architecture approach proved so successful we changed a basic AWS Lambda microservice to an Azure function running a microservice simply by changing the middleware setup in our start-up file. This potentially opens the possibility of building a multiple cloud platform.
The end result was a very stable and highly scalable platform.
The whole solution’s testability was incredibly high, and during the rounds of end-to-end testing, penetration testing, and performance, the team had zero issues that needed to be fixed before going live as everything had been picked up at development time. Naturally, all of that cannot be put down to the approach outlined, however, the team was able to focus much more on the code and less on the runtime, and that increased focus helped produce a better product.
If you would like to find out more about the work we do and problems we solve for our clients, head over to our Success Stories or get in contact.
Date: 14/07/26
By: Digiterre

Date: 30/06/26
By: Ian Murrin

Date: 17/06/26
By: Digiterre

Date: 22/04/26
By: Callum Alston
If you would like to find out more, or want to discuss your current challenges with one of the team, please get in touch.